The Agent Hype Is 1999. Build Like It's 2003.
In 1999, Pets.com raised $82.5 million in an IPO. Nine months later it was gone. The internet was real. The business model wasn't. The mistake wasn't believing in the technology — it was believing the trust and infrastructure would catch up on the schedule the pitch deck required.
I keep thinking about Pets.com when I hear people talk about autonomous AI agents.
Not because agents aren't real. They are. I've been building with them for two years — for enterprises, for logistics platforms, for my own products. They're genuinely transformative. But the mental model driving most of the hype right now is the same category of wrong that took down most of the dot-com era: confusing a correct vision with a present reality.
Here's what I mean.
The core confusion
When people say "agent," what they picture is automation. Deploy it, walk away, collect the output. Set it and forget it. The dream is a bot that runs your workflows while you sleep — deterministic, reliable, unsupervised.
That's not what agents are.
Automation is deterministic. You encode a process, it runs the process, same output every time. That's the whole value proposition — consistency. Predictability. You trust it to run unsupervised because it does the same thing every time.
Agents are probabilistic. They are, at their core, giant probability machines. Every output is a best estimate given context. Two identical inputs can produce meaningfully different outputs. Exceptions aren't handled explicitly — they're guessed at.
That's not a flaw. It's what makes them extraordinary. But it also means the mental model of "automation, but smarter" isn't just wrong — it's the kind of wrong that compounds.
The math nobody wants to look at
When I was building with Cline and watching the context window fill up, I learned something visceral about how these systems fail. It's not one dramatic crash. It's a thousand small wrong turns, each one looking reasonable in isolation.
A 20-step agentic process at 95% per-step reliability — optimistic — only succeeds 36% of the time. Demis Hassabis put it plainly: "If your AI model has a 1% error rate and you plan over 5,000 steps, that 1% compounds like compound interest." By the time you notice, the agent has been confidently wrong for a long time.
I watched this in my own work. The model would declare a feature complete. I'd go look at it. Something was subtly off — not broken, just wrong — in a way that only became obvious three features later when everything built on top of it stopped making sense. The agent had no idea. It was already on to the next thing.
Only 15% of technology leaders are actually deploying autonomous agents in production. The rest are stuck in pilot mode — running demos that look impressive and never make it past testing. That gap between demo and production isn't a capability problem. It's a reliability problem that the autonomy framing makes impossible to solve.
The signals that were flashing in 1999
Here's the thing about the dot-com crash: the internet was real. The vision was correct. Amazon, Google, eBay — they're exactly what the boosters said the internet would produce. The mistake wasn't the vision. It was the assumption that trust and infrastructure would follow capability on the venture timeline.
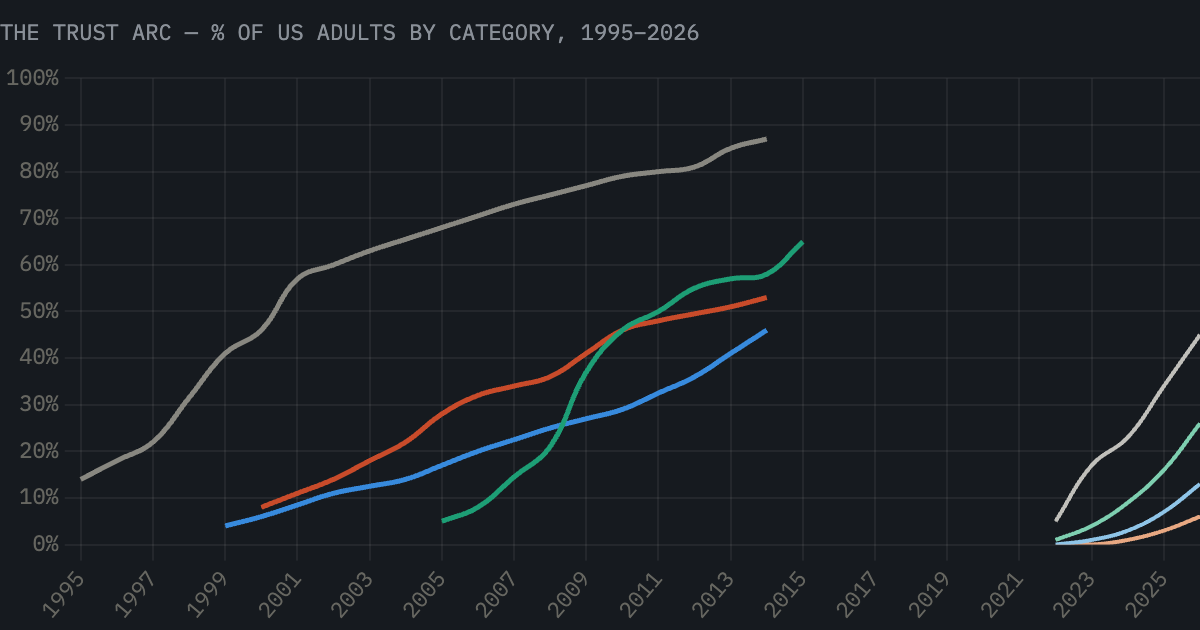
The data on internet trust adoption tells this story clearly.
In 1998, 13% of internet users had ever banked online — not because it didn't work, but because trust doesn't follow capability. It accumulates in stages: information first, then identity, then logistics, then money. By 2013 — eighteen years after the web went mainstream — 51% of US adults banked online. That's the full arc. And the technology was ready years before the trust was.
We are at year four of that arc with AI. The information rung is climbing fast — AI chatbot use hit ~45% of US adults in 2026. But ID, logistics, and finance are barely off zero. Autonomous agents require trust rung four. We are at rung one. The companies burning capital on autonomous agent deployments right now are Pets.com. The infrastructure isn't there. The trust isn't there. The timeline the pitch deck requires does not exist.
The companies that survived the dot-com crash weren't the ones with the boldest vision. They were the ones who built for where trust actually was.
Amazon's stock fell 90% in the crash. It survived because it was building real infrastructure for real customer behavior — not projecting trust that hadn't been earned yet. Pets.com died because its business model assumed a trust level that was years away. The product was fine. The timing was delusional.
But the shock is what should worry you
Here's the part the dot-com parallel makes genuinely unsettling. Trust gaps don't close gradually. They close suddenly, forced by something external nobody planned for.
E-commerce grew at roughly one percentage point of retail share per year for two decades. Steady. Predictable. And then COVID hit.
E-commerce sales jumped 43% in 2020 alone — $244 billion added in a single year. IBM estimated the pandemic accelerated digital adoption by five years. Not because the technology improved. Because an external shock removed the alternative.
Something will do this to AI. A competitive shock. A labor event. Something nobody sees coming. And when the trust gap closes suddenly, every organization that designed their workflows around the autonomy model — unsupervised, no checkpoints, probabilistic systems treated as deterministic ones — is going to face cascading failures at a scale they weren't built to handle. The dot-com survivors had infrastructure. The ones who didn't were already gone.
What the survivors did differently
The question everyone is asking is: how do we make agents more autonomous? Wrong question.
The right question is: how do we make humans radically more productive with agents in the loop?
I learned this building Protogen. The breakthrough wasn't removing humans from the process. It was getting the right humans closer to the material, faster. The agent handles speed and volume. The human handles judgment and consequence. The loop stays tight. You never let the model run far enough ahead that catching an error means unwinding a cascade.
In my own workflow, the things that actually matter — intent, context, craft, speed of evaluation, taste — none of them come from the agent. They all come from the human directing it. The agent is the engine. The human is the driver. You don't remove the driver because the engine got more powerful.
The dot-com survivors built for where users actually were, not where the pitch deck said they'd be. Amazon built fulfillment infrastructure. Google built search that worked. They didn't wait for users to trust the internet with their money before they had a working business. They built real value at the rung where trust already existed, and grew with the arc.
That's the play. Build real productivity at rung one and two. Design your checkpoints. Measure human output, not agent autonomy. Get your infrastructure right before the shock arrives — because when it does, you won't have time to build it.
Two years ago I thought agents were automation — smarter, faster, but fundamentally the same category of tool. I was wrong about that.
What they actually are is something we don't have a clean mental model for yet — probabilistic collaborators that need a human close enough to catch what they miss. Not as a workaround. As the design.
The dot-com crash didn't happen because the internet wasn't real. It happened because people mistook a correct vision for a present reality and built businesses that depended on trust that hadn't been earned.
The agent correction will happen for exactly the same reason.
The question is whether you're building for the crash, or building through it.